User Stories and the Backlog: Vertical vs Horizontal Slicing
As we develop software together, we will naturally come across backlog items that are too big to finish in a single sprint. In fact, we have a word for it: Epic. An epic is simply any user story that is too large to finish in a sprint.
Why is this a bad thing? Why shouldn’t we start work on a backlog item and plan to carry it over from sprint to sprint? There’s biggest reason is that it impacts our ability to reduce risk and improve our product by inspecting and adapting over smaller increments in product. Perhaps the product owner misunderstood the stakeholders needs, or—more likely—seeing the product increment gave the stakeholder a better understanding of their needs.
So, we generally split backlog items until we expect that we can complete them in half a sprint. Why half a sprint? First, the story could take twice as long to complete as expected and we’d still be in good shape. Second, having smaller stories smoothes out our workload and makes our burn-down charts more reliable.
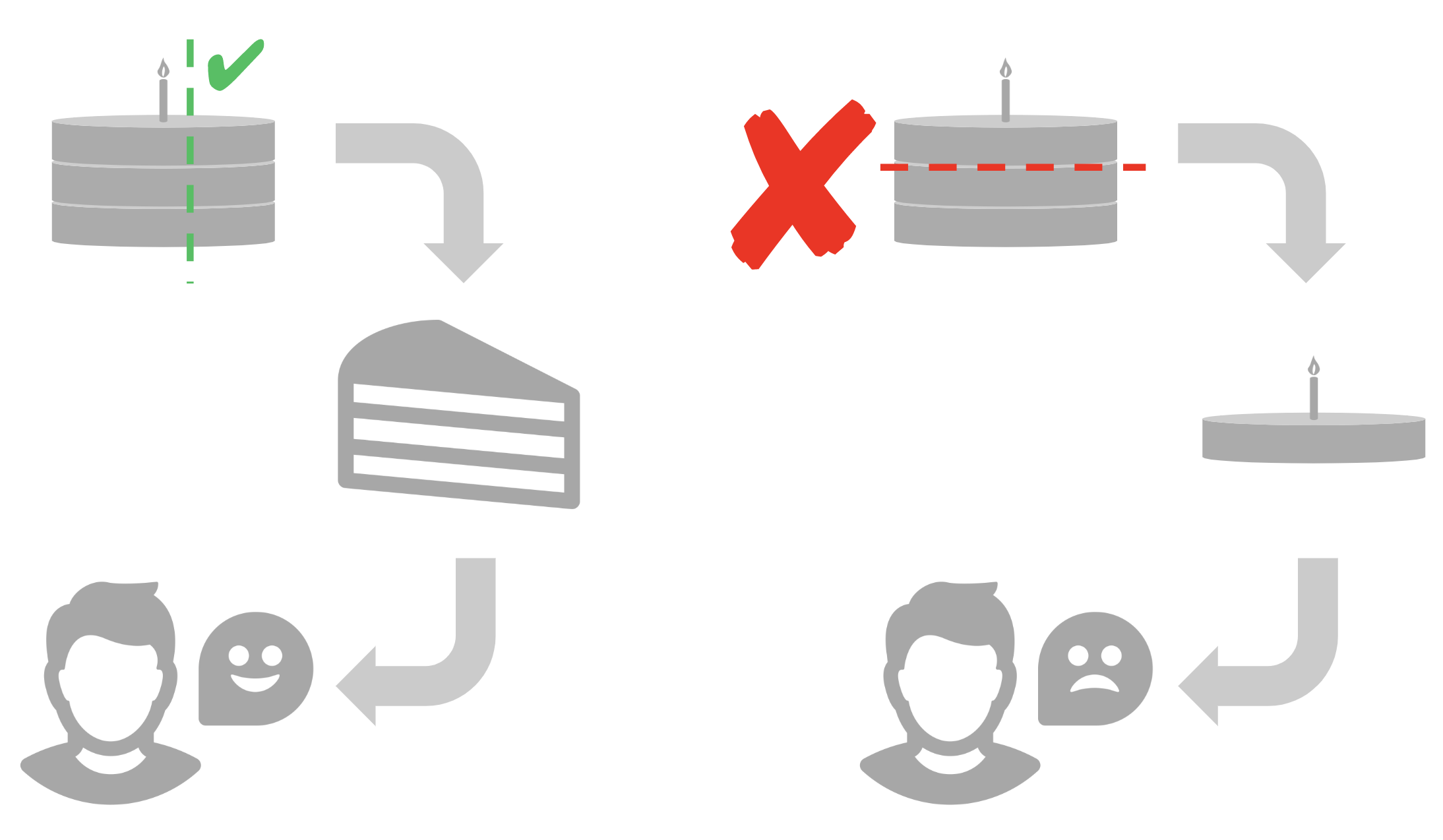
How should we split backlog items? Does it make any difference? Yes, quite a lot. There are two generally ways of splitting stories: vertically and horizontally. These terms come from a cake analogy. When you order a slice of cake at a restaurant, you get a vertical cross-section of the various cooking activities, rather than a thin, horizontal slab of cake without any icing or toppings. In the world of software development, we’ll be dealing with layers such as the presentation, application, business, data access, and infrastructure layers.
Let’s take a software example. Suppose you’d like to create a registration form for a new service. You’d like to let people sign up using their email address or any one of 3 social networks. You’d also like to integrate with your mailing service provider so that you don’t have to manually upload email lists. You could separate this into horizontal slices: first, write engineering requirements for the entire registration flow, then write the business layer, then the data access layer, and so on and so forth. Because you don’t get any working software until the end, this approach lets you down in two ways: first, you can’t capture any value from your customers. In this case we missed out on an opportunity to allow people to register with their email address and start marketing to them. Second, you are likely to learn something when you allow customers to register with their email address. For instance, what if you discovered that the signup success rate was very high and that you didn’t need to add in the social network login yet?
There’s lots of ways of splitting stories vertically. Search for it online and you’ll find many good articles and flow charts. I often like to look at each acceptance criteria on a user story and ask: “Can I ship this user story and gain value and learning without this acceptance criteria being met?” If the answer is yes, you can often create a new user story based on that acceptance criteria. For instance, the story above mentioned an integration with the mailing service provider so that the product marketing manager didn’t have to manually upload the list. Well, can the product marketing manager live with manually uploading the list for the first few weeks so that we turn on registration and start collecting email addresses sooner?
In addition to supporting the inspect and adapt pillars of Scrum, this also supports the Transparency pillar. Your customers won’t be able to see, let alone understand, the code that’s in your repository. Although you can show them mockups and prototypes, there’s nothing like actually getting the functionality in their hands. Another bonus from this approach is that you can start delivering value to your users earlier and more often. Rather than having to wait for every widget to be finished, they can start with the first one you deliver and gain some benefit from it.
A few developers I know don’t like this approach because they feel that it creates throwaway work. Sometimes it does: for instance, if you build an initial version that supports 100 concurrent users, you’ll probably need to rewrite a lot of that code to support 100,000 users. You’d be throwing away a little bit of work. On the other hand, suppose you built out the infrastructure and finished most of the front-end code to support 100,000 users, only to find your project deprioritized. Or suppose the requirements and mocks looked great to your customers, but there was a fundamental flaw in the workflow that they could not have predicted until they started using it. Trading a little throwaway work for the learnings that it can generate can save you from a lot of throwaway work later.